JVM is a engine that provides runtime environment to drive the Java Code or applications. It converts Java bytecode into machines language. JVM is a part of JRE (Java Run Environment). It stands for Java Virtual Machine.
- In other programming languages, the compiler produces machine code for a particular system. However, Java compiler produces code for a Virtual Machine known as Java Virtual Machine.
- First, Java code is complied into bytecode. This bytecode gets interpreted on different machines
- Between host system and Java source, Bytecode is an intermediary language.
- JVM is responsible for allocating memory space.

JVM Architecture
Let’s understand the Architecture of JVM. It contains classloader, memory area, execution engine etc.

1) ClassLoader
The class loader is a subsystem used for loading class files. It performs three major functions viz. Loading, Linking, and Initialization.
2) Method Area
JVM Method Area stores class structures like metadata, the constant runtime pool, and the code for methods.
3) Heap
All the Objects, their related instance variables, and arrays are stored in the heap. This memory is common and shared across multiple threads.
4) JVM language Stacks
Java language Stacks store local variables, and it’s partial results. Each thread has its own JVM stack, created simultaneously as the thread is created. A new frame is created whenever a method is invoked, and it is deleted when method invocation process is complete.
5) PC Registers
PC register store the address of the Java virtual machine instruction which is currently executing. In Java, each thread has its separate PC register.
6) Native Method Stacks
Native method stacks hold the instruction of native code depends on the native library. It is written in another language instead of Java.
7) Execution Engine
It is a type of software used to test hardware, software, or complete systems. The test execution engine never carries any information about the tested product.
8) Native Method interface
The Native Method Interface is a programming framework. It allows Java code which is running in a JVM to call by libraries and native applications.
9) Native Method Libraries
Native Libraries is a collection of the Native Libraries(C, C++) which are needed by the Execution Engine.
Software Code Compilation & Execution process
In order to write and execute a software program, you need the following
- Editor - To type your program into, a notepad could be used for this
- Compiler - To convert your high language program into native machine code
- Linker - To combine different program files reference in your main program together.
- Loader - To load the files from your secondary storage device like Hard Disk, Flash Drive, CD into RAM for execution. The loading is automatically done when you execute your code.
- Execution - Actual execution of the code which is handled by your OS’s processor.
C code Compilation and Execution process
To understand the Java compiling process in Java. Let’s first take a quick look to compiling and linking process in C.
Suppose in the main, you have called two function f1 and f2. The main function is stored in file a1.c. Function f1 is stored in a file a2.c, and function f2 is stored in a file a3.c.
All these files, i.e., a1.c, a2.c, and a3.c, is fed to the compiler. Whose output is the corresponding object files which are the machine code.
The next step is integrating all these object files into a single executable file with the help of linker. The linker will club all these files together and produces the executable.
During program run, a loader program will load the executable into the RAM for theexecution.
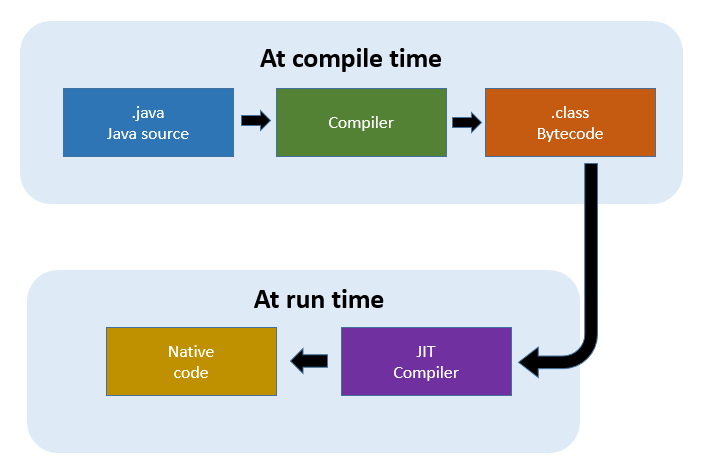
Java code Compilation and Execution in Java VM
Let’s look at the process for JAVA. In your main, you have two methods f1 and f2.
- The main method is stored in file a1.java
- f1 is stored in a file as a2.java
- f2 is stored in a file as a3.java
The compiler will compile the three files and produces 3 corresponding .class file which consists of BYTE code. Unlike C, no linking is done.
The Java VM or Java Virtual Machine resides on the RAM. During execution, using the class loader the class files are brought on the RAM. The BYTE code is verified for any security breaches.
Next, the execution engine will convert the Bytecode into Native machine code. This is just in time compiling. It is one of the main reason why Java is comparatively slow.
NOTE: JIT or Just-in-time compiler is the part of the Java Virtual Machine (JVM). It interprets part of the Byte Code that has similar functionality at the same time.
Why is Java both Interpreted and Compiled Language?
Programming languages are classified as
- Higher Level Language Ex. C++, Java
- Middle-Level Languages Ex. C
- Low-Level Language Ex. Assembly
- The lowest level as the Machine Language.
A compiler is a program which converts a program from one level of language to another. Example conversion of C++ program into machine code.
The java compiler converts high-level java code into bytecode (which is also a type of machine code).
An interpreter is a program which converts a program at one level to another programming language at the same level. An example of an interpretor is that converter of a Java program into a C++ one.
In Java, the Just In Time Code generator converts the bytecode into the native machine code which are at the same programming levels.
Hence, Java is both compiled as well as interpreted language.
Why is Java slow?
The two main reasons behind the slowness of Java are
- Dynamic Linking: Unlike C, linking is done at run-time, every time the program is run in Java.
- Run-time Interpreter: The conversion of byte code into native machine code is done at runtime in Java which furthers slows down the speed.
However, the latest version of Java has addressed the performance bottlenecks to a great extent.
Just-In-Time Compiler
The Just-In-Time (JIT) compiler is a component of the Java Runtime Environment that improves the performance of Java applications at run time.
The key to the Java power “Write once, run everywhere” is the bytecode. The way bytecodes get converted to the appropriate native instructions for an application has a huge impact on the speed of an application. These bytecode can be interpreted, compiled to native code or directly executed on a processor whose Instruction Set Architecture (ISA) is the bytecode specification. Interpreting the bytecode, which is the standard implementation of the Java Virtual Machine (JVM), makes execution of programs slow.
To improve performance, JIT compilers interact with the JVM at runtime and compile appropriate bytecode sequences into native machine code. When using a JIT compiler, the hardware can execute the native code, as opposed to having the JVM interpret the same sequence of bytecode repeatedly and incurring the penalty of a relatively lengthy translation process. This can lead to performance gains in the execution speed, unless methods are executed less frequently. The time that a JIT compiler takes to compile the bytecode is added to the overall execution time, and could lead to a higher execution time than an interpreter for executing the bytecode if the methods compiled by the JIT are not invoked frequently.
The JIT compiler performs certain optimizations when compiling the bytecode to native code. Since the JIT compiler translates a series of bytecode into native instructions, it can perform some simple optimizations. Some of the common optimizations performed by JIT compilers are data-analysis, translation from stack operations to register operations, reduction of memory accesses by register allocation, elimination of common sub-expressions etc. The higher the degree of optimization done by a JIT compiler, the more time it spends in the execution stage. Therefore a JIT compiler cannot afford to do all the optimizations that is done by a static compiler, both because of the overhead added to the execution time and because it has only a restricted view of the program.
How does it work ?
Java programs consists of classes, which contain platform-neutral bytecode that can be interpreted by a JVM on many different computer architectures. At run time, the JVM loads the class files, determines the semantics of each individual bytecode, and performs the appropriate computation. The additional processor and memory usage during interpretation means that a Java application performs more slowly than a native application. The JIT compiler helps improve the performance of Java programs by compiling bytecode into native machine code at run time.
The JIT compiler is enabled by default, and is activated when a Java method is called. The JIT compiler compiles the bytecode of that method into native machine code, compiling it “just in time” to run. When a method has been compiled, the JVM calls the compiled code of that method directly instead of interpreting it. Theoretically, if compilation did not require processor time and memory usage, compiling every method could allow the speed of the Java program to approach that of a native application. JIT compilation does require processor time and memory usage. When the JVM first starts up, thousands of methods are called. Compiling all of these methods can significantly affect startup time, even if the program eventually achieves very good peak performance.
Different compilers for different applications
The JIT compiler comes in two flavors, client or server, and the choice of which compiler to use is often the only compiler tuning that needs to be made when running an application. In fact, knowing which compiler you want to choose is something that must be considered even before Java is installed, since different Java binaries contain different compilers.
A well-known optimizing compiler is C1, the compiler that is enabled through the -client JVM startup option. As its startup name suggests, C1 is a client-side compiler. It is designed for client-side applications that have fewer resources available and are, in many cases, sensitive to application startup time. C1 use performance counters for code profiling to enable simple, relatively unintrusive optimizations.
For long-running applications such as server-side enterprise Java applications, a client-side compiler might not be enough. A server-side compiler like C2 could be used instead. C2 is usually enabled by adding the JVM startup option -server to your startup command-line. Since most server-side programs are expected to run for a long time, enabling C2 means that you will be able to gather more profiling data than you would with a short-running light-weight client application. So you’ll be able to apply more advanced optimization techniques and algorithms.
Tiered compilation
Tiered compilation combines client-side and server-side compilation. Tiered compilation takes advantage of both client and server compiler advantages in your JVM. The client compiler is most active during application startup and handles optimizations triggered by lower performance-counter thresholds. The client-side compiler also inserts performance counters and prepares instruction sets for more advanced optimizations, which will be addressed at a later stage by the server-side compiler. Tiered compilation is a very resource-efficient way of profiling because the compiler is able to collect data during low-impact compiler activity, which can be used for more advanced optimizations later. This approach also yields more information than you’ll get from using interpreted code profile counters alone.
Code optimization
When a method is chosen for compilation, the JVM feeds its bytecode to the Just-In-Time compiler (JIT). The JIT needs to understand the semantics and syntax of the bytecode before it can compile the method correctly. To help the JIT compiler analyze the method, its bytecode are first reformulated in an internal representation called trees, which resembles machine code more closely than bytecode. Analysis and optimizations are then performed on the trees of the method. At the end, the trees are translated into native code. The JIT compiler can use more than one compilation thread to perform JIT compilation tasks. Using multiple threads can potentially help Java applications to start faster. In practice, multiple JIT compilation threads show performance improvements only where there are unused processing cores in the system. The default number of compilation threads is identified by the JVM, and is dependent on the system configuration. If the resulting number of threads is not optimum, you can override the JVM decision by using the XcompilationThreads option. For information on using this option, see JIT and AOT command-line options.
The compilation consists of the following phases:
Inlining
Inlining is the process by which the trees of smaller methods are merged, or “inlined”, into the trees of their callers. This speeds up frequently executed method calls.
Local optimizations
Local optimizations analyze and improve a small section of the code at a time. Many local optimizations implement tried-and-tested techniques used in classic static compilers.
Control flow optimizations
Control flow optimizations analyze the flow of control inside a method (or specific sections of it) and rearrange code paths to improve their efficiency.
Global optimizations
Global optimizations work on the entire method at once. They are more “expensive”, requiring larger amounts of compilation time, but can provide a great increase in performance.
Native code generation
Native code generation processes vary, depending on the platform architecture. Generally, during this phase of the compilation, the trees of a method are translated into machine code instructions; some small optimizations are performed according to architecture characteristics.